Home/Blog
Home/BlogUPDATE: Criticism of the Following Post from The Daily Sceptic
Due to the holidays, I just now saw the post at The Daily Sceptic criticizing my support of the UK Met Office methodology for combining temperature monitoring stations’ data. In retrospect, I should have made it clear that my comments that follow only address the UKMO method for combining stations of various lengths of record, how they “replace” closed stations with surrounding stations, and the use of urbanization-influenced stations. I do not mean to suggest that there are no other time-dependent changes (say, in instrumentation types) that could cause spurious warming in the record. Nor do I claim there are no time-dependent increases in urban heat island spurious biases in the record. I only address (1) the fact that a closed station being replaced with a surrounding station does not necessarily cause problems with long-term monitoring; (2) that the UKMO creation of a fine (1×1 km) grid of UK temperatures from extremely sparse data does not seem to cause spurious trends in the record, and (3) just because a station is poorly-sited doesn’t mean it can’t be used for long-term monitoring. I agree that there are other issues I did not address which impact long-term trends in the UK (or elsewhere). In other words, I was not trying to be comprehensive in my analysis.
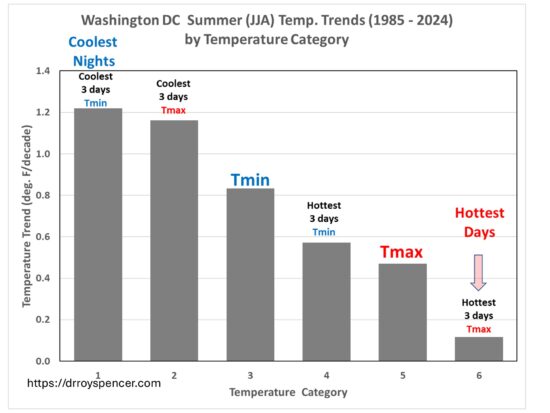
SUMMARY
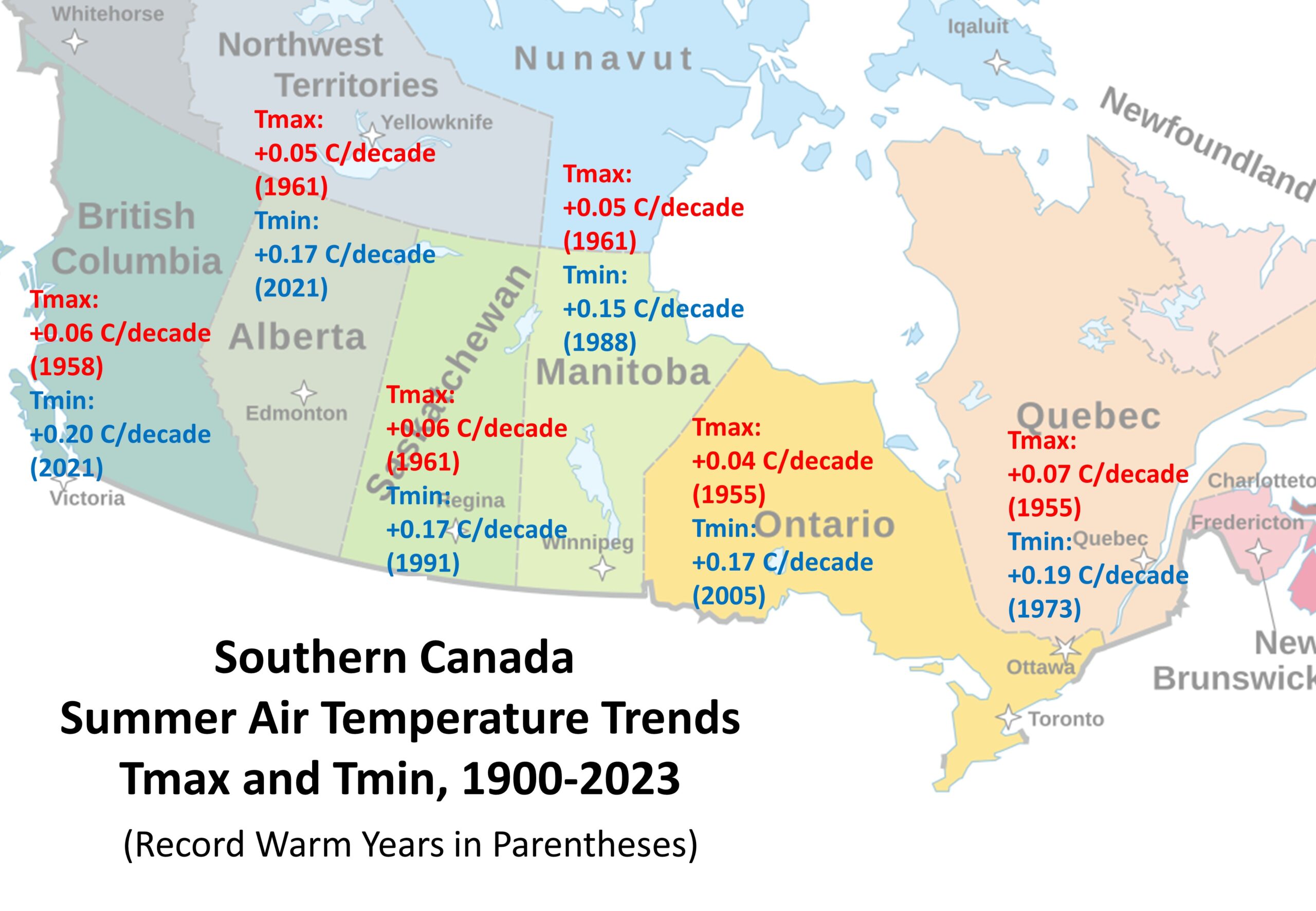
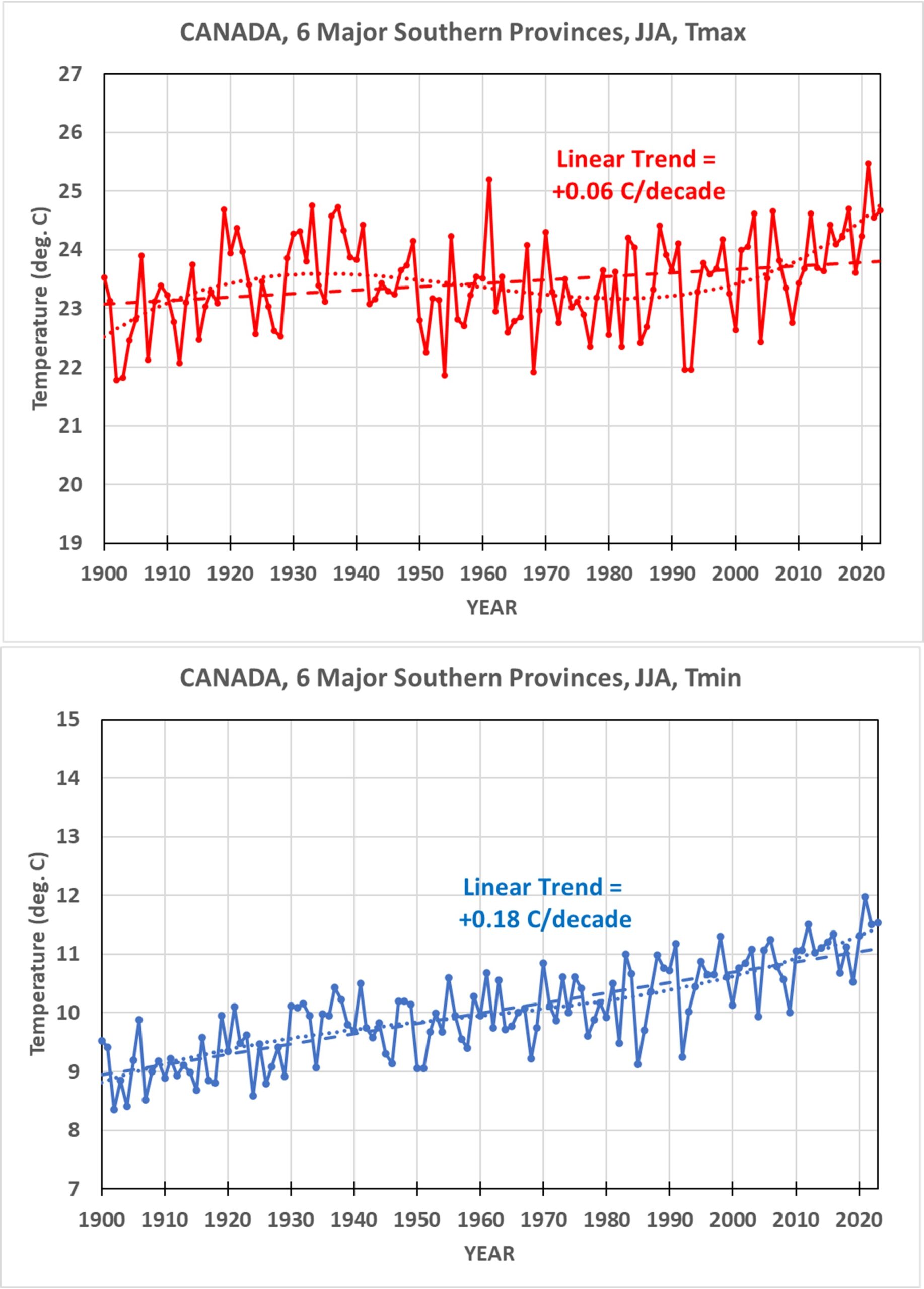
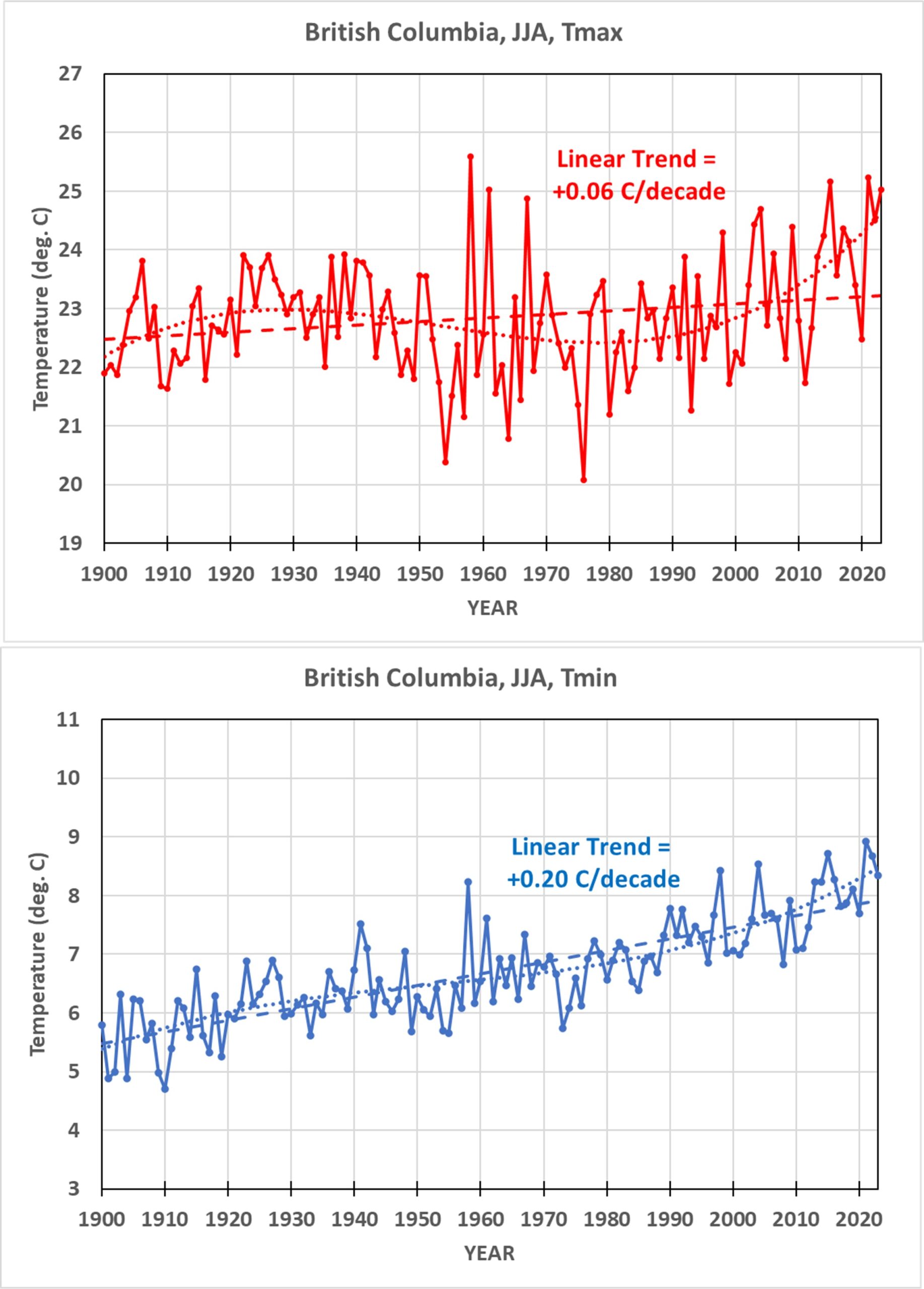
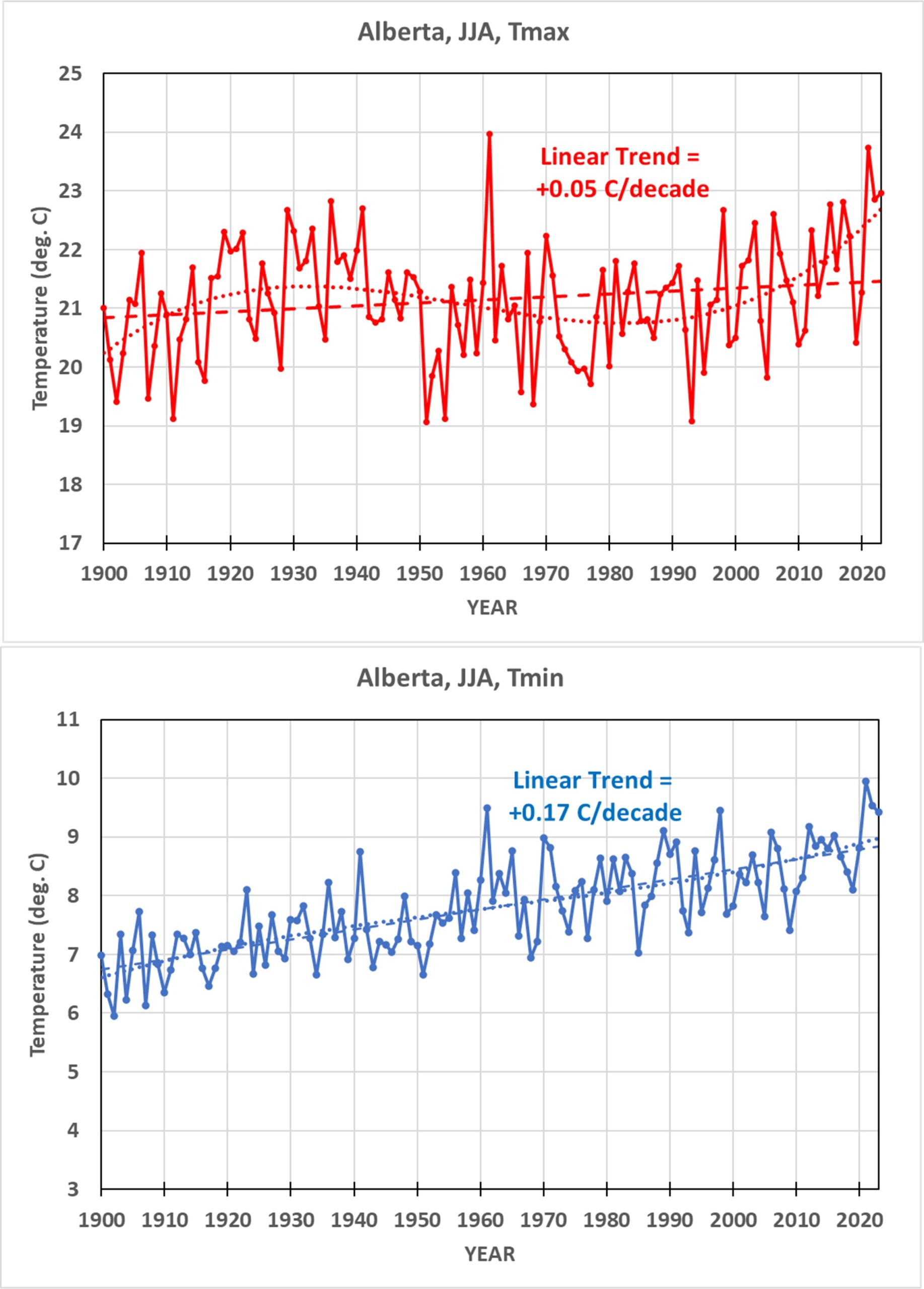
- My analysis of UK daily high (Tmax) and low (Tmin) temperatures during 1960-2025 using a station relative bias removal method produces UK-average summer temperature variations essentially identical to the very different UKMO methodology.
- In both my and the UKMO analysis, 1976 (not 2025) was the hottest summer in daily high temperatures (Tmax), with 2025 taking 3rd or 4th place; the “record” hot year of 2025 was due to nightly low temperatures (Tmin) being anomalously warm.
- The average of the three hottest daytime temperatures in each summer month put the summer of 2025 in 4th place since 1960, behind 1976, 1995, and 2022 (which were essentially identical).
There has been criticism of the UK Met Office’s methodology for monitoring long-term changes in UK-average temperatures, starting with Tallbloke’s (Ray Sanders’) blog post on 31 October 2024. A major criticism that Tallbloke has is the fact that most UK stations do not meet the World Meteorological Organization (WMO) criteria for a good climate monitoring station. The UKMO doesn’t actually use the WMO quality classification system, but their own 4-tiered system. Another criticism is that many UK stations have closed in recent years, and so those stations are, in effect, estimated (“fabricated”?) from surrounding stations.
No Station is Perfect
On the subject of which WMO (or UKMO) class of station is suitable for long-term climate monitoring, I think it’s important to note that a station could be placed in a non-natural, anomalously warm urban environment, but as long as that environment stays the same over time, it can probably still be used for climate change monitoring.
For example, the urban heat island (UHI) effect of London was described over 200 years ago by Luke Howard. Even if London is significantly warmer than the surrounding rural areas, it might be that there has been little additional UHI warming since then, and so a downtown London weather station might be adequate for monitoring large-scale climate change, since I have no reason to believe that (say) 1 deg. C of large-scale warming will lead to city warming substantially different from 1 deg. C.
On the additional subject of replacing a closed station with estimates from surrounding stations (which NOAA also does because so many of their UNHCN stations in the U.S. have closed, a process that has also been criticized), I believe it is a little disingenuous to claim those data are “fabricated”. Rather than continuing the closed station record with estimates from surrounding stations, one could just use the surrounding stations, which is the same thing.
The UKMO’s Fancy High-Resolution Mapping of UK Temperatures
The Met Office divides the UK land mass into tiny (1×1 km) grid cells, and the temperature in each one is estimated from the nearest station(s) using average, regression-based adjustments for elevation, latitude, longitude, terrain shape, coastal proximity, and land use variations. The result is a seemingly complete coverage of UK for the purpose of temperature monitoring:
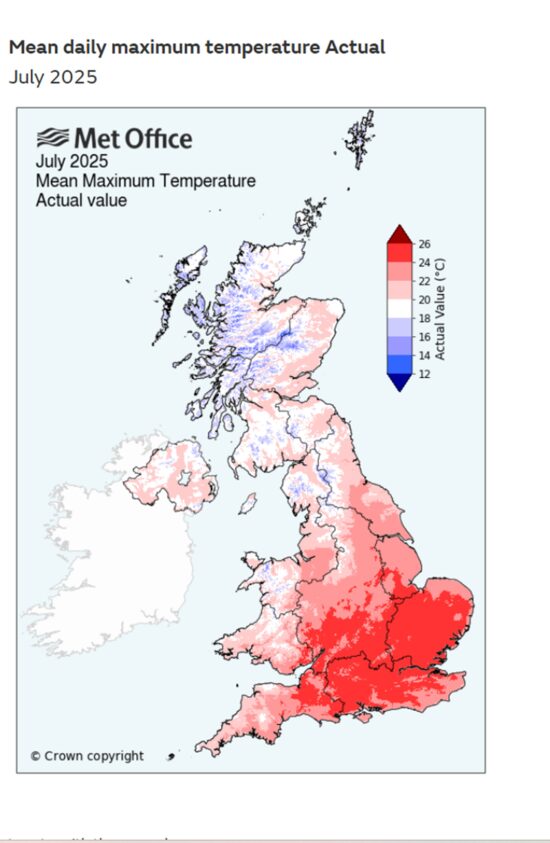
And I get why this is done: the UKMO primary mission is to provide daily weather monitoring and forecasts, and given limited station data providing actual measurements, their system provides useful temperature estimates in areas far removed from actual weather stations.
Of course, all of this high-resolution fanciness must be anchored by actual measurements, and in the daily Global Historical Climate Network (GHCNd) database, only ~100 stations exist across the UK in recent years. (There were very few GHCNd stations before 1960, so I will address temperature change only since then here). This means only 1 in ~2,400 UK grid cells has an actual temperature monitoring station in the GHCNd dataset, which is the dataset all global temperature monitoring efforts rely upon. While the UKMO might have access to somewhat more stations than are included in the GHCNd dataset, my point will remain valid.
Nevertheless, this doesn’t mean that long-term climate change can’t be monitored with the existing station network. What complicates matters is that stations come and go over time, and this can introduce biases that change over time and corrupt long-term estimates of temperature change. How one accounts for, and adjusts for, these changes is not a settled matter.
Removing Relative Biases Between Stations
From what I’ve been able to glean, the UKMO does not actually calculate and remove relative biases between stations. Instead, they use the above-described strategy to evaluate how station temperatures vary with latitude, longitude, elevation, proximity to the coast, land use (e.g. urbanization), etc., then apply regression-based techniques to estimate temperatures on the 1×1 km grid. This has no doubt involved considerable effort, and having done similar kinds of data analysis myself, it’s a complex task.
A simpler way of monitoring climate change is to assume that long-term (in the current example, 65 years) warming trends that actually exist in nature are pretty uniform across the UK. If this assumption holds, we can just take whatever stations exist over time, no matter where they are located or what their local microclimate-induced biases are, and quantify how the temperatures at each one varies over time, and then average all of those variations together. This methodology is somewhat similar to that of Hansen and Lebedeff, 1987, as well as our UAH satellite global temperature dataset.
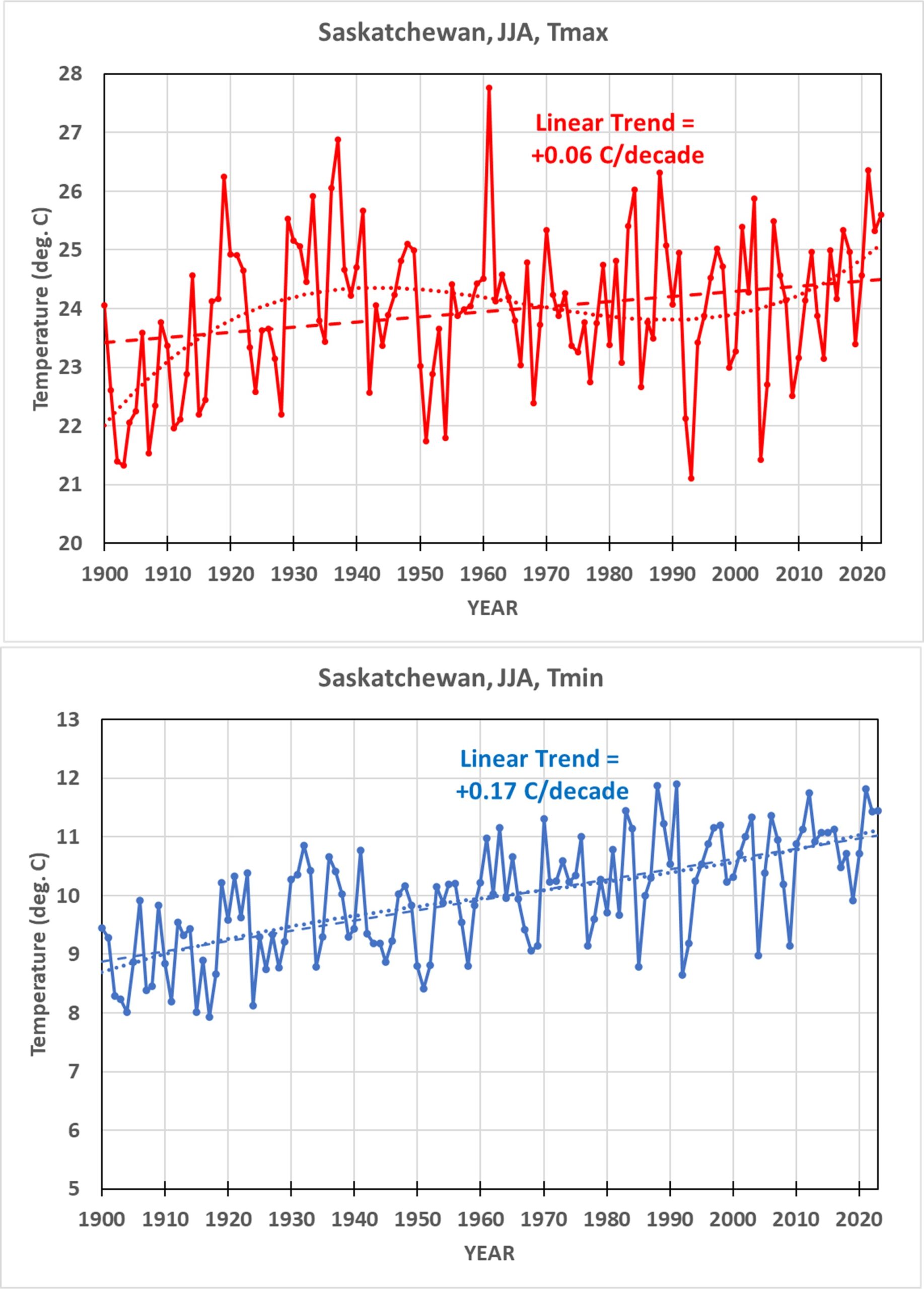
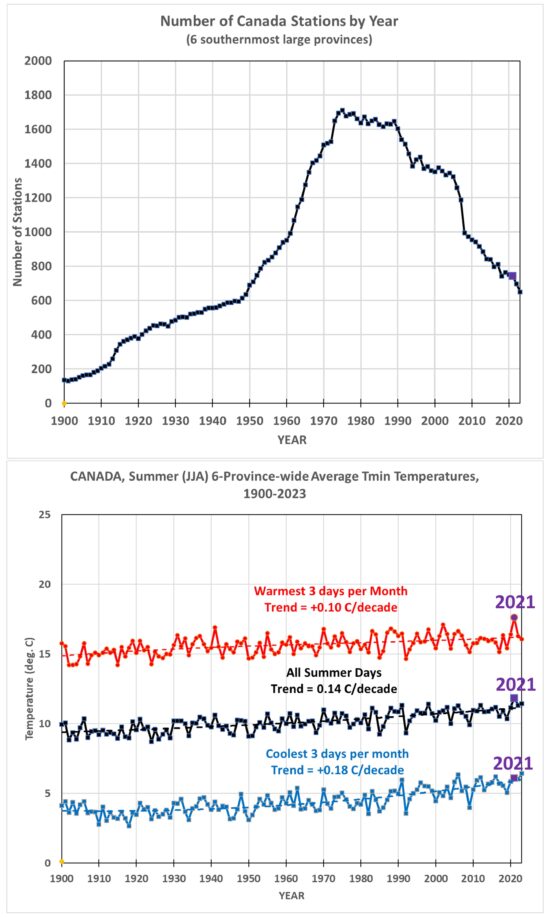
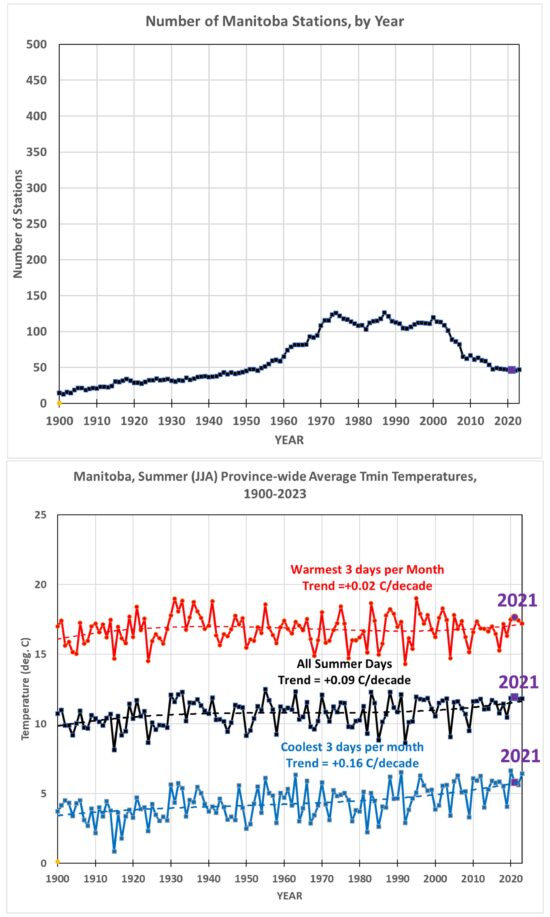
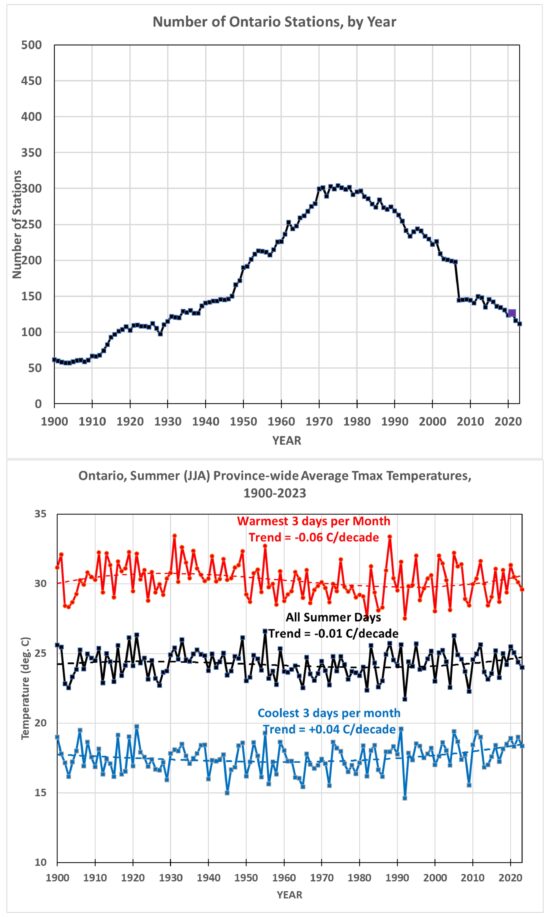
In my implementation of this relative bias removal method, I start with the stations having the longest periods of record. In the UK, only 3 stations have had continuous records in all 126 years from 1900 to 2025: CET Central England, Armagh, and Stornoway Airport. (Only 31% of the UK stations had periods of record at least half as long, 63+ years). I average those 3 stations together. Then, I take the station(s) with the next-longest record (Oxford, 124 years), compute the average difference with the original series, and add it to the series to make a new 4-station average. This is done sequentially for all (148) stations in the UK since 1900 that have at least 2 years of record, going down the list from the longest periods of record to the shortest. Again, since there were few stations before 1960, the following plots cover variations since 1960.
Amazingly, the result using this simple relative bias removal method produces yearly summer-average temperatures (average of daily high [Tmax] and daily low [Tmin]) that are nearly identical to the much fancier UKMO methodology:
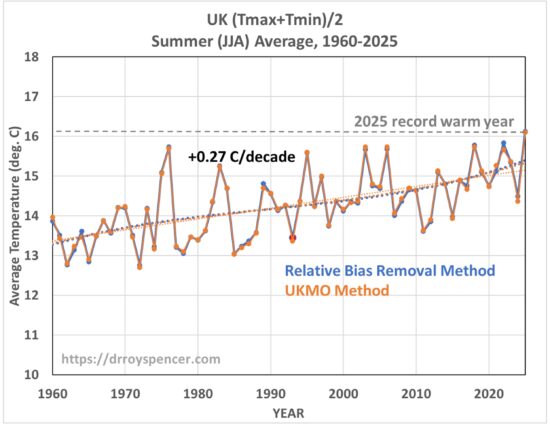
In this plot (as well as the others, below) for display purposes I have removed a small (~1-2 deg C) temperature offset due to my use of the original 3 stations for an absolute temperature baseline, whereas the UKMO uses their gridded estimate of the entire area of the UK. The linear trends in the above plot are essentially identical, at +0.27 C/decade.
But that record high did not exist for the daytime high temperatures. As seen in the next plot, 2025 was very similar to several years since 1995, while 1976 holds the record for hottest summertime daily high temperatures:
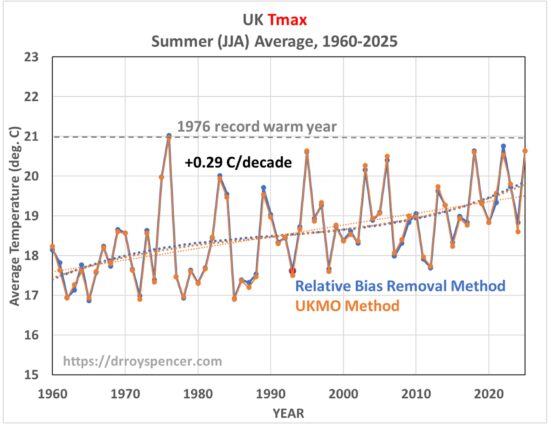
So, where did the 2025 record come from? It was due to the nighttime temperatures being so warm (although I don’t see how 53 deg. F is is insufferably warm). This was true in both analyses of the station data:
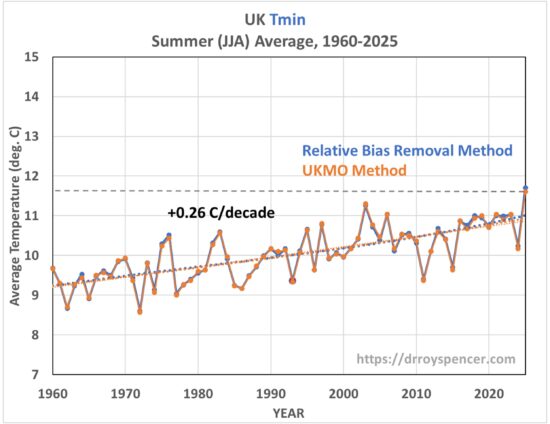
Finally, since I am analyzing daily temperature data, I can compute the average of the three hottest daytime temperatures in each summer month, which produces this:
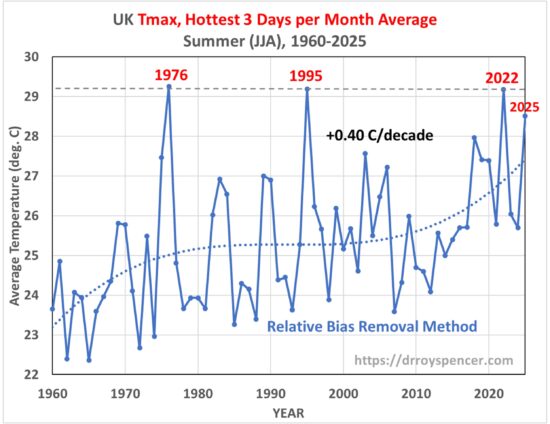
For this statistic we see that the record is a 3-way tie between 1976, 1995, and 2022. We also see a stronger warming trend (+0.40 C/decade vs ~+0.26 C/decade in all-days average Tmax and Tmin). I suspect this is due to more Saharan air intrusions in recent decades, which are the primary cause of excessively hot days in the UK.
Conclusions
Despite criticisms of the UKMO data and methods for computing UK-average temperatures, I find that a simple bias-removal method of combining all available UK stations produces essentially identical results to the much more complex UKMO methodology. It should provide some vindication for the UKMO methodology in the context of climate temperature trend monitoring.
The record hot summer of 2025 in the UK was in the nightly minimum temperatures, not in the daytime maximum temperatures. This is true in both my analysis and that of the UKMO.
Finally, neither my nor the UKMO method accounts for possible changes in stations over time, such as an increasing urban heat island (UHI) effect at some stations. Based upon our work on this in recent years I suspect this effect since 1960 would be small, but I don’t know that for sure.